CAPÍTULO 1
GENERALIDADES
1.1.- INTRODUCCIÓN
Los sistemas de síntesis de voz, son aquellos que convierten una entrada escrita en palabras, a una salida pronunciada, simulando el proceso humano de leer en voz alta. Estos sistemas son también conocidos como sistemas de texto a voz (TTS, siglas de las palabras en inglés Text – To - Speech) [WEB 1].
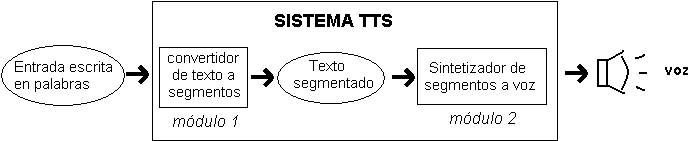
Los sistemas TTS, que se han construido, tienen dos módulos [WEB 2] que actúan entre sí, para realizar la síntesis de voz y que son ilustrados en la figura 1.1. El primer módulo es un convertidor de texto a segmento, es decir, recibe el texto de entrada y lo separa en partes más pequeñas llamadas segmentos. En el segundo módulo, llamado sintetizador de segmentos a voz, se convierten dichos segmentos a sonidos, generando una voz artificial, que interpreta el texto de entrada.
Figura 1.1 Sistema de texto a voz
1.1.1.- TIPOS DE SEGMENTOS
Los diferentes tipos de segmentos mostrados en la tabla 1.1 han sido tomados como base para desarrollar el módulo convertidor de texto a segmentos de un sistema TTS [WEB 3].| Tipo de Segmento |
Descripción |
|
Palabra |
Conj. de sonidos articulados que expresan una idea [varios autores, 1985] |
|
Sílaba |
* Menor unidad de impulso respiratorio [varios autores, 1985] * Uno o más símbolos fonéticos que representan una unidad básica de una palabra fonológica[WEB 9] |
|
CVC |
Consonante – Vocal – Consonante |
|
VCV |
Vocal – Consonante – Vocal |
|
Difonema |
Sucesión transitoria de sonidos [WEB 8] |
|
Pseudofonema |
No definida por los autores [WEB 7] |
|
Demisílaba |
No definida por los autores [WEB 7] |
|
Subfonema |
No definida por los autores [WEB 7] |
Tabla 1.1 .- Tipos de segmentos
No se encontraron referencias donde se abordará el segmento de tipo fonema es por eso que no se menciona en la tabla anterior, sin embargo, solo como mención a este segmento, se puede decir que es la unidad básica de la sílaba[WEB 9].
1.1.2.- CLASIFICACIÓN: SISTEMAS DE VOCABULARIO LIMITADO E ILIMITADO
Existen dos tipos de sistemas TTS [WEB 4], de vocabulario limitado y de vocabulario ilimitado. Su clasificación depende del tamaño del vocabulario que utilizan. Los sistemas limitados usan los segmentos de tipo palabra o sílaba; siendo limitados porque cuentan con un número finito o limitado de palabras o sílabas en su vocabulario.
Los sistemas TTS de vocabulario ilimitado se caracterizan por poder sintetizar un número ilimitado de palabras y generalmente emplean segmentos más pequeños que la sílaba para lograr este objetivo. Para ilustrar lo mencionado anteriormente, véase la figura 1.2.

Figura 1.2 Clasificación de sistemas TTS
1.2.- ANTECEDENTES
Los sistemas TTS que se han desarrollado hasta el momento para el idioma español, han tenido un avance muy pobre comparado con el idioma inglés.
En la tabla 1.2 se presentan los institutos de investigación que han trabajado en sistemas TTS y el idioma para el que desarrollaron sus sistemas [WEB 6].
|
Instituto |
Idioma (s) |
|
YORK TALK |
Inglés |
|
University of Birmingham |
Inglés europeo y americano |
|
Dec Talk |
Inglés |
|
Ipox |
Alemán |
|
Eurovocs |
Japonés, Inglés, Alemán, Español y Francés |
Tabla 1.2 Desarrollos en sistemas TTS
Obsérvese que sólo el instituto Eurovocs, ha desarrollado sistemas TTS para el idioma español. Algunas implementaciones realizadas con los diferentes tipos de segmentos hasta la fecha experimentados, se muestran en la tabla 1.3 [WEB 5].
|
Tipo de segmento |
Experimentos |
|
Palabra |
Buron 1986, chapman 1971 |
|
Sílaba |
Ouh-Young 1986 |
|
CVC |
Hayashi y Murakami 1992 |
|
VCV |
Sato 1978 |
|
Difonema |
Lefevre 1986 |
|
Pseudofonema |
Mikuni y Ohta 1986 |
|
Demisílaba |
Lovis y Fujimora 1976 |
|
Subfonema |
El-Iman 1989, Dan y Dutta 1991 |
Tabla 1.3 Implementaciones de sistemas TTS
1.3.- DESCRIPCIÓN DEL PROBLEMA Y JUSTIFICACIÓN
El interés original que motivo esta investigación, es el de darle la capacidad de producir voz artificial a las computadoras, es decir, que la computadora sea capaz de leer cualquier texto en el idioma español.
Esta capacidad proporcionaría otra forma de comunicación entre la computadora y el hombre. Podría ser útil para ayudar a minusválidos, invidentes o personas con problemas de comunicación.
Otra utilidad que se le puede dar a este sistema, es en ambientes de trabajo donde los que laboran ahí tengan su vista ocupada y al mismo tiempo tengan que recibir información del proceso que realizan.
Analizando la estructura de las palabras en el idioma español, se observa que cada palabra es divisible en una o más sílabas, es por eso que, en este trabajo se eligió la sílaba como segmento, para dividir las palabras. Otra razón para escoger este tipo de segmento, es por ser un conjunto de sonidos que pueden ser pronunciados en una sola emisión de voz[varios autores, 1972].
Otro segmento con la misma justificación que el segmento de tipo sílaba, es el segmento de tipo fonema, sin embargo se tiene la gran desventaja comparada con el segmento de tipo sílaba, que al unir dos fonemas es muy importante la coarticulación entre ellos.
El principal problema al que se enfrentan los sistemas TTS es la producción de voz "natural", esto es, que deben contener sonidos naturales como inflección vocal, ritmo, acentuación, coarticulación entre sílabas, la velocidad de pronunciación de las sílabas de una palabra [Keller, 1992], la no uniformidad en tono y volumen de cada sílaba, y las pausas entre una sílaba y otra.
Como un ejemplo de todos los problemas mencionados anteriormente se sugiere al lector que lea un texto en voz alta, en sílabas, haciendo caso omiso de los signos ortográficos, así como de la acentuación de las sílabas, con la finalidad de que se pueda percibir la importancia de cada uno de estos problemas.
1.4.- OBJETIVO DE LA TESIS
El objetivo de esta tesis, es desarrollar un sistema de síntesis de voz de vocabulario limitado para el idioma español. El sistema usa un tipo de segmento silábico y debe ejecutarse en una computadora personal bajo el sistema operativo MS-Windows. La computadora utilizará una tarjeta de sonido para la entrada y salida de voz.
1.5.- DESCRIPCIÓN DE LOS CAPÍTULOS
Este capítulo presenta una breve introducción a los sistemas de síntesis de voz, su clasificación, los antecedentes que se tienen sobre investigaciones pasadas, así como también se plantean los problemas a los que se enfrentan estos sistemas y finalmente se presenta la justificación de esta tesis. Este capítulo es necesario que se lea, para comprender el capítulo 3.Como el segmento escogido para esta tesis es la sílaba, en el capítulo 2 se describen las reglas del idioma español para su formación, así como su estructura y clasificación. En este capítulo se justifica el algoritmo planteado en esta tesis para realizar la segmentación de una palabra en sílabas.
El capítulo 3 presenta la arquitectura del sistema elaborado, describiendo cada una de las fases de este sistema, las cuales son: grabación de los archivos de sonido, generador de voz y la interfaz de usuario.
Los resultados de la experimentación realizada con este sistema, se detallan en el capítulo 4, así como también se describen los principales problemas abordados en el desarrollo de este. En este capítulo se presenta una aplicación de este sistema a un tutorial hablado.
Para finalizar los capítulos de esta tesis, se presentan las conclusiones de este trabajo y las propuestas planteadas para trabajos futuros, de un sistema como este, en el capítulo 5.
En la sección de apéndices se puede encontrar información acerca de los archivos de sonido con formato WAV usados en esta tesis, el listado de los programas desarrollados para este sistema, junto con un manual de usuario de cada uno de esto programas.